はじめからの分散メッセージングシステム ~Part3.真の分散処理を目指して~
分散メッセージング基盤と聞いて何を思い浮かべるでしょうか。
最近流行りのchatGPTに尋ねてみたところ、以下の回答が返ってきました。
分散メッセージング基盤(Distributed Messaging Infrastructure)とは、複数のコンピューターやデバイス間で情報をやり取りするためのシステムのことを指します。 分散メッセージング基盤は、分散型システムを構築する際に使用されることが多く、スケーラビリティや可用性を高めることができます。また、分散メッセージング基盤は、リアルタイムでの情報交換やデータのやり取りが必要なアプリケーションでも使用されることがあります。例えば、複数のデバイスで同期して動作するゲームや、IoT(Internet of Things)デバイスでの情報収集などです。
上記に記載の通り、データのやり取りが必要なアプリケーションで使われるような技術です。
Apache KafkaやAmazon Kinesisなんかは聞いたことがある人もいるのではないでしょうか。
本記事では単純なノード間のやり取りからはじめて、メッセージング基盤、および"分散"メッセージング基盤まで解説することを目指します。最後には主要な製品の解説も入れるつもりです。

本記事はPart3です。 以前の記事はこちら
目次
管理者ノードの省略
さて、前回の記事では分散の概念を導入したモデルを作成しました。 しかしながら、ノードの管理を担うための管理者ノードが必要で完全な"分散"とは言えないようなシステムでした。
さて、ここからさらなる分散を目指すためにはどうしたらよいでしょう。
言い換えると管理者をなくして、実ノードだけで運用するにはどうしたらよいでしょうか。
まるで社会のようですね。複数の人たちで意見をまとめるにはどうしたらよいでしょう。
早い者勝ち? じゃんけん? 暴力?
やっぱり民主主義の根幹となる考えである、”多数決”でしょうか。
そうです、システムの世界も”多数決”で物事を決定することにしました。
これを支える技術はいくつかありますが、代表的なものがRaftと呼ばれる技術です。
詳細は下記のアニメーションが非常にわかりやすいので、先に見ていただくとよいかもしれません。
Raftの概要なら以下
Raft: Understandable Distributed Consensus
細かい動作を理解したいなら以下
では見ていきましょう。先ほと同様に”分散”が可能になるのは2台からなのでそこからスタートしましょう。先ほどは管理者がいましたが、今回はキューしかいないので相互に通信しあう必要がありますね。

ここで管理者不在のために問題になることと解決策についてみてみましょう
先ほどの仕組みだと管理者に問い合わせに行くことでユーザはリーダーの位置を知ることができました。今回は管理者が不在なので、ユーザはどこに投げてよいかわかりません。。。
どうしましょう。仕方ありませんので、ランダムに投げることにしましょう。
上記の図だと①が青のメッセージ管理をするリーダー、②が赤のメッセージを管理するリーダーです。偶然赤のメッセージが②のノードに届くこともありますし、①のノードに行ってしまうかもしれません。ここで受け取ったノードが処理してしまうと順序性が失われてしまうので処理をルーティングしてあげることにしましょう。(サーバサイドのルーティング)
もちろん、Aさんに②が担当だから、改めて②を宛先にして送り返してということもできるでしょう。(クライアントサイドでのルーティング)
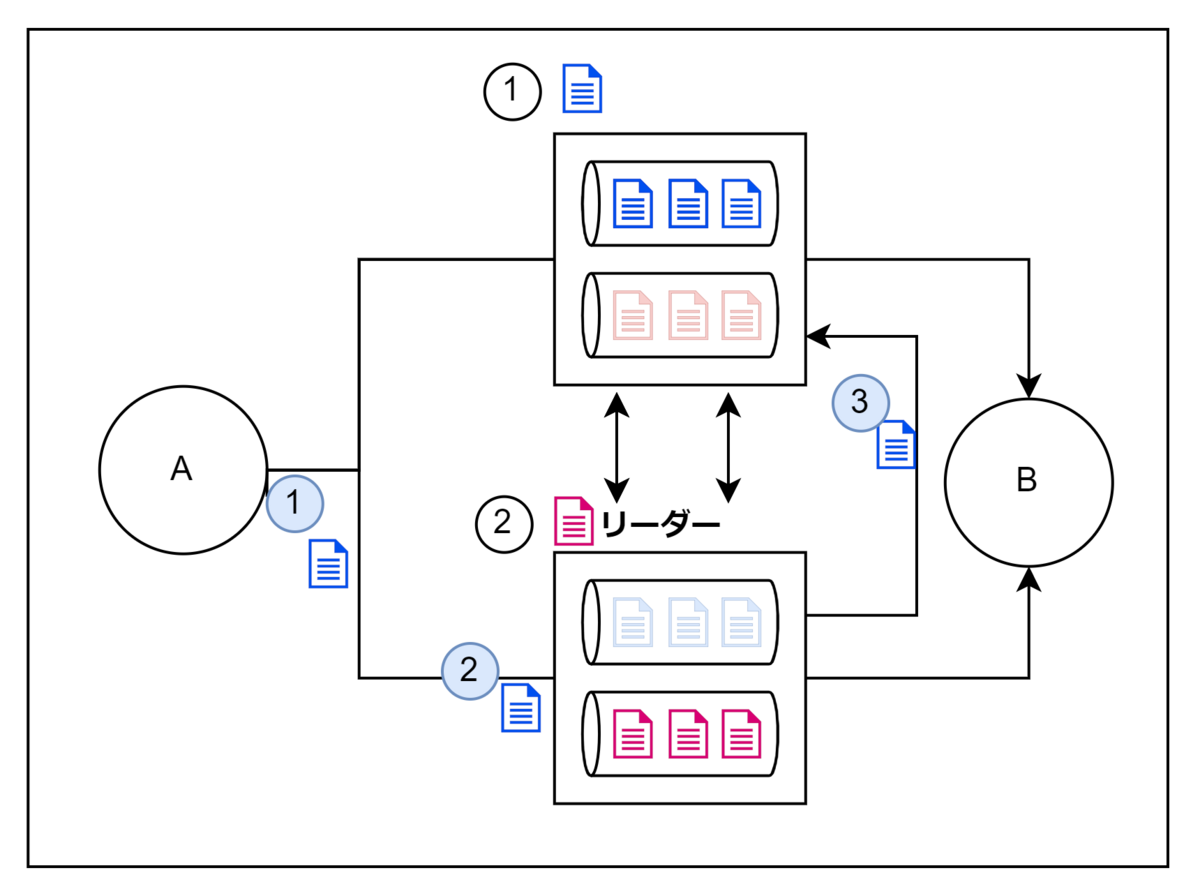 上記の図は青のメッセージにもかかわらず、②のノードが受け取ってしまったので、②のノードにルーティングしています。
上記の図は青のメッセージにもかかわらず、②のノードが受け取ってしまったので、②のノードにルーティングしています。
はい、これで”管理者”なしの分散構成の完成です。
では毎度同じみの障害の場合を考えてみましょう。
単一ノードの障害時の挙動について
①のノードが障害により使えなくなったとします。 ②は定期的に通信していた①からの通信が途絶えるので、複製されていたデータをもとにリーダーに昇格して処理を継続しようとします。

問題なさそうですね。ではもっと難しいケースを考えてみましょう。
ネットワーク障害時の挙動について

①と②のネットワークが一時的に通信できなくなってしまった状況です。最初のケースと異なる点は①は実際にはまだ生きていてリーダーとして機能し続けるという点です。
この場合でも②から見ると通信が途絶したように見えるので、リーダーに昇格しようと試みます。
つまり、リーダーが複数存在することになってしまいました。と、どうなるでしょう。
どちらもリーダーだと思って処理し続けるので、メッセージの順番が崩れてしまいますね。加えて、ネットワークが復活したらどうなるでしょう。
このままだと障害が起こった際にメッセージが失われてしまうので、急いでメッセージの状態を同期させる必要があります。しかし、①、②どちらも自身のメッセージが最新だと思っているので同期がうまくいきません。
さて、困りました。それぞれ自身が最新だと主張しあっていることが問題なわけです。では多数決の概念を導入して、多数派が正解とみなすことにしましょう。1台障害時にも多数決を行うためには最低3台必要になりますね。
多数決の導入
1台のリーダーに対して、2台のフォロワーを作成することとしましょう。以下のようになりますね。

ではここからまたスタートしてみましょう。先ほど問題であったネットワークの障害を見ていきましょう。
ネットワーク障害時の挙動について

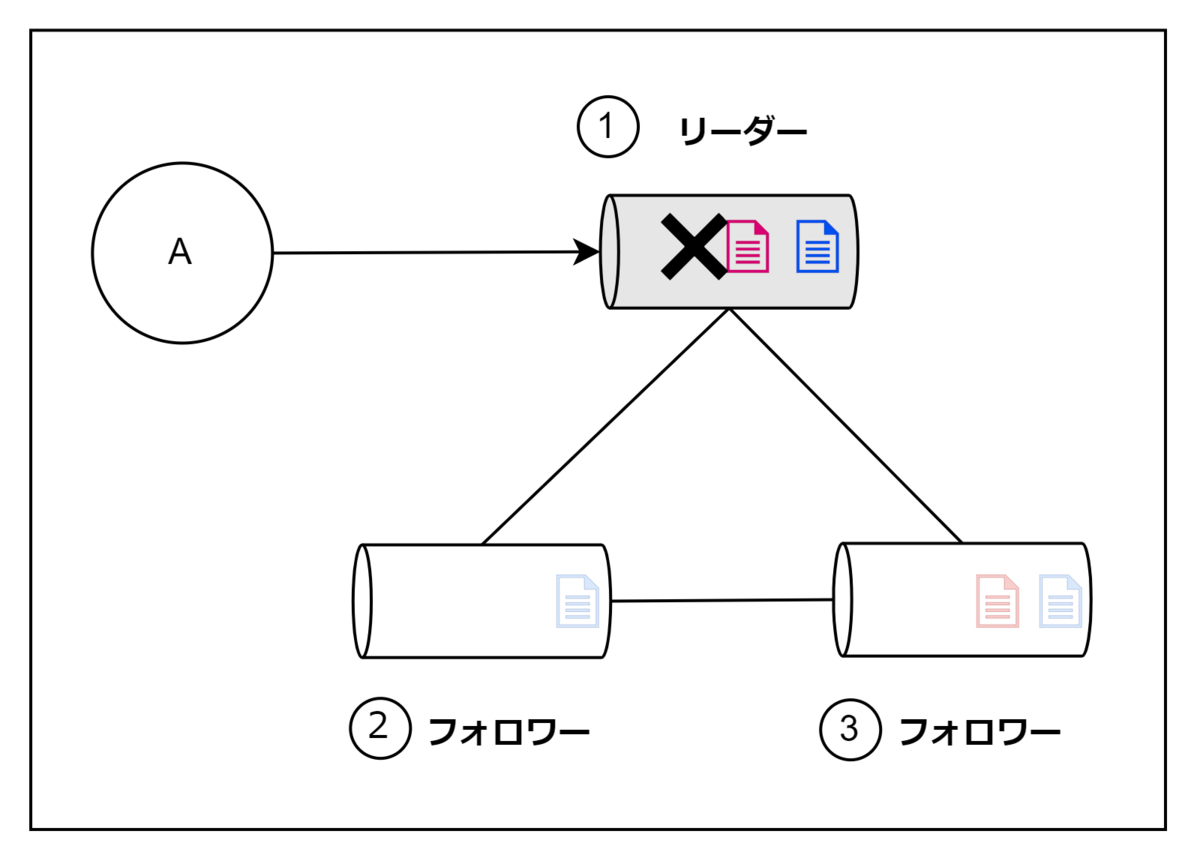
上記は②のノードが①と通信できない状態です。前回同様に①には障害が発生していませんが、②からは①が障害が発生したように見えるのでリーダーに昇格しようと試みます。ここで”多数決”を取ります。②は自身と接続しているノードにリーダーになってもいいか尋ねるリクエストを送ります。3台の多数決なので、②は自身を含むさらにもう一台の同意を得ることができればリーダーになることはできます。しかし、③はまだリーダーが存在していることがわかっているため、②のリクエストを却下します。②は過半数の同意を得ることができなかったので、リーダーになれませんでした。これは正しい動作ですので先ほどの問題は解決できそうですね。
では、特殊な障害ではなく、本当に①が障害で通信できなくなった場合を考えましょう。
単一ノードの障害時の挙動について

この場合どちらかがリーダーになるかはランダムで決まります。細かく説明すると、フォロワーはリーダーからの死活監視に対して待つ時間をランダムに決めています。したがって、先にタイムアウト(待ちきれなくなった)方から、先にリーダーになってもよいか問い合わせるリクエストを送ります。
今回の場合は②が先にタイムアウトにリーダーになってもよいかリクエストを出した状態です。
①は当然障害なので応答がないですが、③は断る理由もないのでリクエストに対して許可を出します。②は自身を含む過半数のノードから同意を得られたため、無事リーダーになることができました。ここら辺は先ほど挙げたアニメーションを見ていただくと理解が深まるかと思います。
最後に正常動作の場合を見てきましょう。
正常動作時の挙動について

以下のような処理になります。
- ユーザがリーダーに対してメッセージを送ります。(仮にフォロワーがデータを受け取った場合は内部でルーティングします)
- リーダーはフォロワーに対して、合意形成を行います。(平たく言うと多数決ですね)
- フォロワーは自身の管理テーブルにデータをエントリさせます。
- 過半数から合意が得られたら、リーダーはメッセージの処理を確定させます
- ユーザに対して完了した旨のメッセージを出します
ここでな要素が二点あります。
リーダーは過半数からの合意が得られるまで処理を確定させません。これを同期処理といいますが、確実に他のノードに情報が伝播されたタイミングで処理を確定させます。今回の場合だと①+②or ③のどちらかの同意が得られれば処理を確定させます。
確実にデータを複製するなら全ノードからの応答を待ったほうが良いんじゃない?と思われた方もいるかもしれません。
結論からいつと、最低限過半数の複製が完了すればよいのです。
むしろ、全ノードからの応答を待っていると、たまたまあるノードの応答が遅かった場合に全体の処理確定のタイミングが遅れ、結果としてユーザへ結果を連携するのが遅くなってしまいます。
補足_過半数で充足する理由について
ではなぜ過半数で充足するのかを見ていきましょう。 以下は青→赤の順番でメッセージを送信した場合の図です。 ①はリーダーであり、③の連絡をもって赤のメッセージを確定させたものの、②に反映される前に①が障害になってしまった状態です。
①(リーダー)赤、青のメッセージを両方保持
②(フォロワー) 青のメッセージのみ保持
③(フォロワー)赤、青のメッセージを両方保持
正常状態であれば、定期的にリーダーと最新の情報をやり取りしているので、②は自身が持つデータが古いことに気づき追いつきをかけます。
今回の例は追いつきを実施する前に①が障害になってしまった場合です。
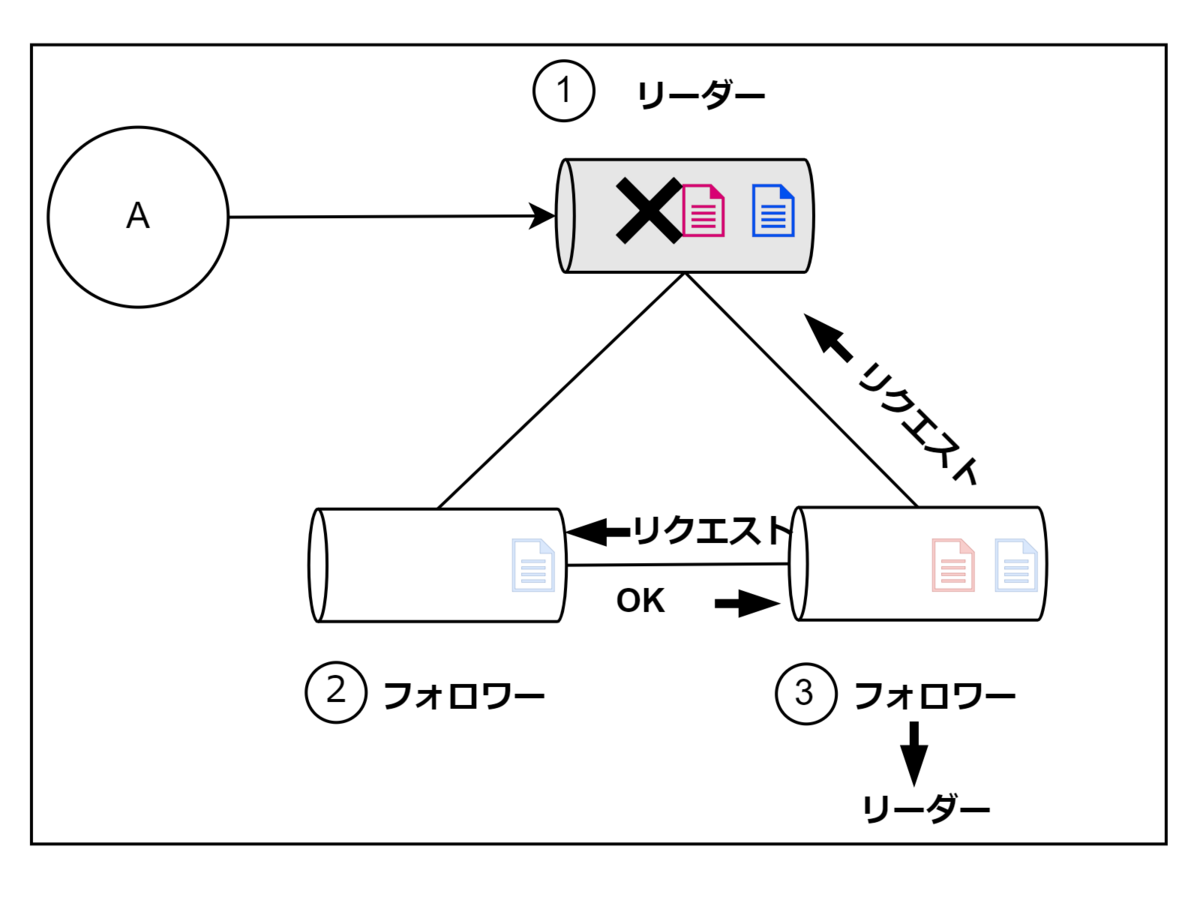
先ほど説明したようにフォロワーはリーダーからの死活監視が途絶えると、ランダム時間待ってリーダーになってもよいかリクエストを送ります。今回はたまたま②が先にタイムアウトに達してリクエストを送った場合です。③は②からのリーダーリクエストを受信した際に、②の状態を見ます。(正確にはメッセージに②の最新の状態が送られてきます)
③は②がリーダーにふさわしいか審査をするわけなのですが、自身のほうが最新(赤のメッセージを持っているため)であるためリクエストは却下します。

代わりに③はリーダーリクエストを出します。②は③は自身よりも最新であるためこと悪い理由もなく、リクエストを承認します。結果として③がリーダーとなります。
つまり障害を考慮した場合、最低でも”過半数”の合意が得られれば問題ないのです。 むしろ、全ノードの応答を待っているとユーザへ処理確定の連絡が遅れ、レイテンシの悪化につながります。
はい、ここまで長い道のりでしたが、やっと管理者不在での分散処理の完成です。
まとめ
前回時点で管理者ありの分散メッセージングシステムを構築しました。 ネットワークパーティションの問題に弱い構成でしたが、”多数決”の概念を導入することで 、正常時、障害時ともに動作することを確認しました。
最後に分散メッセージングシステムの各製品のアーキテクチャを見てみましょう。ここまで理解してきたら容易に頭に入ってくるはずです。AWS、GoogleCloudの製品も見ていきましょう。
はじめからの分散メッセージングシステム ~Part2.分散基盤の導入~
分散メッセージング基盤と聞いて何を思い浮かべるでしょうか。
最近流行りのchatGPTに尋ねてみたところ、以下の回答が返ってきました。
分散メッセージング基盤(Distributed Messaging Infrastructure)とは、複数のコンピューターやデバイス間で情報をやり取りするためのシステムのことを指します。 分散メッセージング基盤は、分散型システムを構築する際に使用されることが多く、スケーラビリティや可用性を高めることができます。また、分散メッセージング基盤は、リアルタイムでの情報交換やデータのやり取りが必要なアプリケーションでも使用されることがあります。例えば、複数のデバイスで同期して動作するゲームや、IoT(Internet of Things)デバイスでの情報収集などです。
上記に記載の通り、データのやり取りが必要なアプリケーションで使われるような技術です。
Apache KafkaやAmazon Kinesisなんかは聞いたことがある人もいるのではないでしょうか。
本記事では単純なノード間のやり取りからはじめて、メッセージング基盤、および"分散"メッセージング基盤まで解説することを目指します。最後には主要な製品の解説も入れるつもりです。
本記事はPart2です。 以前の記事はこちら
目次
分散メッセージングシステムの導入と課題
さて、前回の記事ではメッセージングシステムの導入とその課題について説明してきました。
前回のメッセージングシステムでは以下の問題がありました。
障害時の切り替えに数秒程度の時間がかかる(Active-Standbyであるため)
単一サーバで処理を行うため、リソースの限界がある
性能向上のためには待機系もあわせてスペックアップする必要があるため、コスト対性能比が良くない
上記の課題を解決するために「分散メッセージングシステム」が登場しました。
偉大なる先人たちは思いました、アクティブ-スタンバイがだめなら、アクティブーアクティブにすればよいじゃないかと!
またディスク装置も共有しているので、それぞれでデータを持つことにしましょう。

先ほどはメインとサブ号機があり、どちらかしか稼働していませんでしたが今回はどちらも稼働しています。
しかし、これには二つの問題があります。
- メッセージの順序は保証されません。
- どちらかが障害になった際に片方のデータは失われてしまいます。
順番が保証されない問題について

①赤、青の順番でAからメッセージが送信されました。
②それぞれ別のノードが赤と青のメッセージを受け取りました
③さて、どちらのメッセージが先にBに到着するでしょうか。
直感的には赤が最初に送ったのだからBに到着するのも赤が最初になりそうな気がしますね。
ただ赤のメッセージが通る経路が混雑していたらどうでしょう、あるいは赤のメッセージを受け取ったキューが仕事で手一杯だったらどうでしょう。
答えは送った通りの赤、青の順番で届くこともあれば、青、赤の順番で届くこともあります。
つまり「順番が保証されない」のです。
障害時のデータ保証について

こちらはイメージしやすいかと思います。前回の記事ではディスクを共有することでデータの消失を防いでいましたが、データも処理も"分散"してしまったので、障害が発生したノードが管理していたメッセージは失われてしまいます。
課題解消に向けて
先の問題を解決するためにモデルを更新しましょう。 障害時にもデータを保全できるように、ノード間で複製を行うこととしましょう。
また順序保証の仕組みのために「パーティションキー」と呼ばれる概念を導入しましょう。 モデルは以下のように更新されます。

順番が保証されない問題について
先ほどは完全にランダムに振り分けていたので、順序を保つのは難しいということでした。
そのままでは順序を保つのが難しいので、メッセージごとにそれぞれの担当を決めましょう。
担当を振り分けるためになんらかの目印が必要ですね。一般的には「パーティションキー」と呼ばれます。
図では①が青のメッセージ担当、②が赤のメッセージ担当です。
完全に順番を保証することはできませんが、少なくともパーティションキーが同じメッセージは同じノードが担当するので順序を保つことができます。
なので、順序を保ちたいメッセージは同じパーティションキーにしてあげればよいことになります、例えばIoTでの用途を考えた際に、IoTデバイスを一意に特定できるIDをパーティションキーとして設定してあげることで、異なるIoTデバイス間ではBで受け取る順番が異なる可能性がありますが、同じデバイスでは時系列が保証されます。
障害時のデータ保証について
図中の濃い色がオリジナルのメッセージ、薄い色が複製されたメッセージを表しています。 それぞれが担当するメッセージを複製して、別ノードに持たせることで単一ノード障害時にもデータを保全することが可能です。
管理者ノードの導入によるさらなる改善
さて、ここまでのモデルで十分問題ないように見えてきますね。 ただ悲しいかな、まだいくつかの問題が存在します。
例えば、②が障害により赤のメッセージを送信できなくなったらどうしましょう。
①が赤の複製メッセージを持っているので代わりに送信を担当することができますね。
あれ、この判断は自分たちでやるのでしょうか。
ほかにもユーザが新しくメッセージの振り分け定義を追加する場合はどうすればよいのでしょうか。どちらかのノードのみに変更を行えばよいのでしょうか。
上記のような種々の管理を行うために「管理者」ノードを作成することにしましょう。
管理者は便宜上の呼び名であって、本構成の一般的な呼び方ではないので注意してください。

①も②も管理者にお伺いたててから操作を実行します。
また管理者の指示によってリーダーを変更したりします。 まるで平社員と上司の関係のようですね!キューは実働(メッセージの送信を担当)し、管理者はメッセージの送信は担当しませんが、管理データを用いて指示だしを行います。
今度こそよさそうですね!
しかし、あなたはふと思うのかもしれません。これで”分散”?
管理者に頼ってる時点で完全な”分散”とは言えないんじゃないかと
次回はさらなる発展形となります。
そこで導入された概念がRaftによる分散処理です。最近の分散メッセージングシステムは上記の考え方を踏襲しているものがとても多いです。
はじめからの分散メッセージングシステム ~Part1.メッセージング基盤とは~
分散メッセージング基盤と聞いて何を思い浮かべるでしょうか。
最近流行りのchatGPTに尋ねてみたところ、以下の回答が返ってきました。
分散メッセージング基盤(Distributed Messaging Infrastructure)とは、複数のコンピューターやデバイス間で情報をやり取りするためのシステムのことを指します。 分散メッセージング基盤は、分散型システムを構築する際に使用されることが多く、スケーラビリティや可用性を高めることができます。また、分散メッセージング基盤は、リアルタイムでの情報交換やデータのやり取りが必要なアプリケーションでも使用されることがあります。例えば、複数のデバイスで同期して動作するゲームや、IoT(Internet of Things)デバイスでの情報収集などです。
上記に記載の通り、データのやり取りが必要なアプリケーションで使われるような技術です。
Apache KafkaやAmazon Kinesisなんかは聞いたことがある人もいるのではないでしょうか。
本記事では単純なノード間のやり取りからはじめて、メッセージング基盤、および"分散"メッセージング基盤まで解説することを目指します。最後には主要な製品の解説も入れるつもりです。
目次
メッセージング基盤導入前
あるサーバ間でデータを受け渡したいと思うときどのような仕組みを考えるでしょうか。
一番単純な例だとこのようになります。

非常にシンプルですね。まずはここからスタートしましょう。「データを受け渡す」という点は上記で満たせそうですね。
でも次の場合を考えてみるとどうでしょう。

1. 送り先を追加したい場合
Aはすべての送信先を知っている(設定する)必要があります。また送信先の追加のたびに変更作業をする必要があるでしょう。 また送信元が追加した場合は、その送信元ごとに宛先の追加作業を行う必要があります。
2. 送信先が(オフラインであり)受け取れない状態
送信先がオンラインとなるまでAは待ち続けなくてはいけません。定期的にオンラインかどうかを確認する仕組みも必要でしょう。
3. 送信先が(処理量を超えており)受け取れない状態
AがBの処理量を超えるスピードでメッセージを送っているためにBの負荷が大きくなっている状態です。この状態ではBがいずれメッセージを受け付けなくなってしまいます。最悪の場合メッセージをロストしてしまうこともあるでしょう。
メッセージング基盤導入後
そこで登場したのが「メッセージングキュー(=メッセージング基盤)」という仕組みです。 送信したいノードの間にメッセージを保持して管理するキューを挟むことによって上記の問題を解決します。

さてもう一度、先ほどやりたかったことがどのように解消されるか見ていきましょう。
1. 送り先を追加したい場合
送信元Aはキューに対する宛先だけわかればよくなります。もし、送信元が増えた場合でもすべからずキューに対してメッセージを送ればよくなりますので、宛先の設定は一か所になります。宛先の制御はキューにて行いますので、変更が一か所で済むようになります。 送信先の制御にはメタ情報を付与して送ることになります。 例えば、以下のように本文とは別に送り先を指定してあげるイメージです。
送り先→B宛て
本文→テストメッセージ
キューはその情報に基づき、送り先を変えます。 こちらはキューイングシステムによって「Subject」であったり、「キュー名」だったりと呼称は異なりますが、どちらもメッセージの種類を区別しそれによって宛先を変更します。
2. 送信先が(オフラインであり)受け取れない状態
Aはキューに対してメッセージを投げます。Aはキューにメッセージを投げたタイミングで処理を完了し、次のメッセージの処理が可能になります。 キューはBがオンラインになったタイミングでメッセージを配送します。 AはBの状態を気にすることなく、次の処理を行うことができます。
3. 送信先が(処理量を超えており)受け取れない状態
キューが送信の流量制御を行います。つまりAから受け取ったメッセージをそのまま流すのではなく、Bが処理できる流量に落として配信を行います。
メッセージングキューが備えるべき条件
さて、ここまで「メッセージングキュー」のメリットについてみてきましたが、キューが備えるべき条件も明らかになってきたはずです。
まずは送信先の代わりにデータを受け取るので、キューシステムは常に使用可能な状態にしておく必要があります。もし使えない場合は送信元はデータを送れず、当初の1の課題と同じことになってしまいます。
またメッセージを”確実”に届けるためにデータをロストしてはいけません。
つまり以下が大事な要件ということになります。
・可用性
・堅牢性
では可用性を高めるためにはどのようにしたらよいでしょうか。
システムといっても機械なので人為的なミス、ハードウェアの故障、ソフトウェアのバグによってシステムがダウンしてしまうことは発生してしまいます。
まず思いつくのはサブ機を用意することです。
障害が起きたタイミングでサブ機に切り替えを行えば、処理が継続できますね!
では堅牢性を高めるにはどのようにしたらよいでしょうか。
データを単一で持つのではなく、2重、3重と複製することで、あるデータが障害により失われてしまった場合でも復旧が可能です。
つまり以下のような構成が望ましいでしょうか。

メッセージング基盤の問題点
上記のモデルは非常によくワークします。
しかしながら、サブ機の切り替えのタイミングで数秒程度使えない状態が存在します。
メイン機が障害が起きたことに気づき、処理開始するまでに多少の時間がかかるからです。
これまではそれでもデータ量が少ない、システムが使えないことによるビジネスインパクトが今ほどは大きくないため許容されてきました。
しかし、昨今はデータドリブンな社会へと変革しており、データが処理できないことがおおきな機会損失、ビジネス上へのネガティブインパクトを与えます。
また、データ量が増えてきて処理量も膨大なものになってきた場合どのように対処するでしょうか。
リソースのスペックをあげることで対応することにしました。
ただし、単一サーバのリソースには限界があり、どこまでもスペックアップできるわけではありません。
また障害時に同様の流量をさばくために、普段は使っていないのにもかかわらず待機系もスペックアップする必要があり、コストが増加します。
上記の課題を解決するために生まれたのが分散メッセージング基盤となります。 分散と聞くと、大型の企業が非常にたくさんのサーバを用意して処理を行っていることをイメージされるかもしれませんが、いまや各種クラウドベンダーの力により、個人であっても比較的容易にクラウドネイティブな処理が可能になっています。 次の章で分散メッセージング基盤の特徴と解決した課題を見ていきましょう。 (次に続く)